layout: false name: title class: left, bottom background-image: url("figuras/title-slide.001.jpeg") background-size: contain .pull-left[ # .midlarge[.black[Oficina de análise de dados NIR em ambiente R]] ## .mid[.black[Partes 4—5 - LDA e PLS]] #### .large[.black[Ricardo Perdiz (Luz da Floresta) | 2021/07/02]] ] <div class="cr cr-top cr-left cr-sticky cr-black">COVID19</div> --- layout: true <div class="cr cr-top cr-left cr-sticky cr-black">COVID19</div> <a class="footer-link" href="https://github.com/ricoperdiz/oficina-dados-nir">Análise de dados NIR em R</a> --- # Sumário ### [Recapitulação](#recapitulacao) do primeiro dia -- ### Interface para análise de dados do [*caret*](#caret) -- ### Análise discriminante linear ([LDA](#lda)) -- ### Análise de mínimos quadrados parciais ([PLS](#pls)) --- name: recapitulacao # Recapitulação .pull-left[ 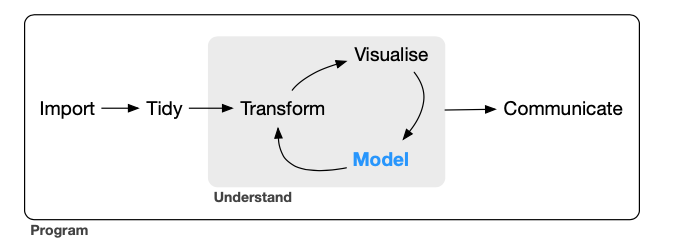 ] .pull-right[ #### Manipulação de dados utilizando o *dplyr* #### Preparação de dados pré-análise #### PCA ] .footnote2[ Figura de Wickham, H. e Grolemund, G. (2016) <http://r4ds.had.co.nz>. ] --- name: dados # Importando dados para a oficina .pull-left[ ## Opção 1 - Dados `iris` ``` r dados <- iris ``` ## Opção 2 - Importação de dados próprios ``` r library("data.table") dados <- fread("MEUSDADOS.csv") ``` ] .pull-right[ ## Opção 3 - Conjunto de dados `nir_data`<sup>1</sup>, que acompanha o pacote `NIRtools`<sup>2</sup>. ``` r dados <- fread("https://raw.githubusercontent.com/ricoperdiz/NIRtools/master/inst/extdata/nir_data.csv") ``` ] --- ## Transformação do `data.frame` em um `tibble`<sup>1</sup> ``` r library("tibble") dados <- as_tibble(dados) dados ``` ``` ## # A tibble: 150 × 5 ## Sepal.Length Sepal.Width Petal.Length Petal.Width Species ## <dbl> <dbl> <dbl> <dbl> <fct> ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa ## 4 4.6 3.1 1.5 0.2 setosa ## 5 5 3.6 1.4 0.2 setosa ## 6 5.4 3.9 1.7 0.4 setosa ## 7 4.6 3.4 1.4 0.3 setosa ## 8 5 3.4 1.5 0.2 setosa ## 9 4.4 2.9 1.4 0.2 setosa ## 10 4.9 3.1 1.5 0.1 setosa ## # ℹ 140 more rows ``` .footnote2[ 1. Este passo **NÃO É NECESSÁRIO**. Ele facilita apenas a visualização dos dados no console, e indica o tipo de cada variável em seu conjunto de dados. Saiba mais sobre um `tibble` em [https://r4ds.had.co.nz/tibbles.html](https://r4ds.had.co.nz/tibbles.html). ] --- ## Atenção!!! ### Nova variável de nome de espécies Em casos em que a variável contendo o nome da espécie apresente espaços, pontos `.` e/ou sinais diferentes, é necessário limparmos essa variável caso desejemos reter os valores de probabilidade atribuídos a cada espécie ao utilizarmos o *caret*. Em casos assim, podemos tomar o procedimento abaixo: ``` r library("dplyr") ``` ``` r dados$SP1 <- case_when( dados$SP1 == "P. aracouchini" ~ "arac", dados$SP1 == "P. calanense" ~ "cala" ) %>% as.factor(.) ``` --- # Pré-processamento dos dados -- ## Divisão dos dados em `treino` e `teste` ``` r library("rsample") # initial_split dados_split <- initial_split(dados, strata = "Species") treino <- training(dados_split) teste <- testing(dados_split) ``` --- name: receita ## Criação e preparo da receita ``` r library("recipes") treino_receita <- recipes::recipe(Species ~ ., data = treino) %>% prep() treino_receita ``` ``` ## ``` ``` ## ── Recipe ──────────────────────────────────────────────────── ``` ``` ## ``` ``` ## ── Inputs ``` ``` ## Number of variables by role ``` ``` ## outcome: 1 ## predictor: 4 ``` ``` ## ``` ``` ## ── Training information ``` ``` ## Training data contained 111 data points and no incomplete ## rows. ``` --- # PCA ## I - PCA com todos os dados? Primeiro, criamos uma receita indicando no argumento `data` o nome de nosso conjunto de dados. Depois fazemos as devidas atualizações dos papéis das variáveis que não são nem preditoras nem resposta com a função `update_role()`. Em seguida, executamos a PCA com a função `step_pca()` para todas as variáveis NIR, utilizando a função auxiliar `all_predictors()` para, por fim, prepararmos a receita com a função `prep()`. Depois, é só plotar os dados *espremendo* a receita, o que vai gerar uma PCA com os dados completos. --- ## I - PCA com todos os dados? ``` r dados_completos_receita_pca_pre <- recipes::recipe(Species ~ ., data = dados) %>% step_normalize(all_predictors()) %>% step_pca(all_predictors()) %>% prep() dados_completos_receita_pca_pre ``` ``` ## ``` ``` ## ── Recipe ──────────────────────────────────────────────────── ``` ``` ## ``` ``` ## ── Inputs ``` ``` ## Number of variables by role ``` ``` ## outcome: 1 ## predictor: 4 ``` ``` ## ``` ``` ## ── Training information ``` ``` ## Training data contained 150 data points and no incomplete ## rows. ``` ``` ## ``` ``` ## ── Operations ``` ``` ## • Centering and scaling for: Sepal.Length, ... | Trained ``` ``` ## • PCA extraction with: Sepal.Length, ... | Trained ``` --- ## II - PCA com todos os dados? ``` r pca_tabela <- tidy(dados_completos_receita_pca_pre, 2) pca_tabela ``` ``` ## # A tibble: 16 × 4 ## terms value component id ## <chr> <dbl> <chr> <chr> ## 1 Sepal.Length 0.521 PC1 pca_f6kUq ## 2 Sepal.Width -0.269 PC1 pca_f6kUq ## 3 Petal.Length 0.580 PC1 pca_f6kUq ## 4 Petal.Width 0.565 PC1 pca_f6kUq ## 5 Sepal.Length -0.377 PC2 pca_f6kUq ## 6 Sepal.Width -0.923 PC2 pca_f6kUq ## 7 Petal.Length -0.0245 PC2 pca_f6kUq ## 8 Petal.Width -0.0669 PC2 pca_f6kUq ## 9 Sepal.Length 0.720 PC3 pca_f6kUq ## 10 Sepal.Width -0.244 PC3 pca_f6kUq ## 11 Petal.Length -0.142 PC3 pca_f6kUq ## 12 Petal.Width -0.634 PC3 pca_f6kUq ## 13 Sepal.Length 0.261 PC4 pca_f6kUq ## 14 Sepal.Width -0.124 PC4 pca_f6kUq ## 15 Petal.Length -0.801 PC4 pca_f6kUq ## 16 Petal.Width 0.524 PC4 pca_f6kUq ``` --- ## III - PCA com todos os dados? ### Variação das PC's ``` r sdev_pca_normalizada <- dados_completos_receita_pca_pre$steps[[2]]$res$sdev porcent_variacao_normalizada <- sdev_pca_normalizada^2 / sum(sdev_pca_normalizada^2) pca_normalizada_variacao <- data.frame( pcs = unique(pca_tabela$component), variacao_porcentagem = porcent_variacao_normalizada*100, variacao_cumulativa = cumsum(porcent_variacao_normalizada*100) ) pca_normalizada_variacao ``` ``` ## pcs variacao_porcentagem variacao_cumulativa ## 1 PC1 72.9624454 72.96245 ## 2 PC2 22.8507618 95.81321 ## 3 PC3 3.6689219 99.48213 ## 4 PC4 0.5178709 100.00000 ``` --- ## IV - PCA com todos os dados? .pull-left[ ### Plotando PCA com dados completos ``` r library("ggplot2") pc1 <- filter(pca_normalizada_variacao, pcs == "PC1") pc2 <- filter(pca_normalizada_variacao, pcs == "PC2") juice(dados_completos_receita_pca_pre) %>% ggplot(aes(PC1, PC2)) + geom_point(aes(color = Species), alpha = 0.7, size = 2) + xlab(paste0("PC1 (", round(pc1$variacao_porcentagem, 2), "%)")) + ylab(paste0("PC2 (", round(pc2$variacao_porcentagem, 2), "%)")) ``` ] .pull-right[ 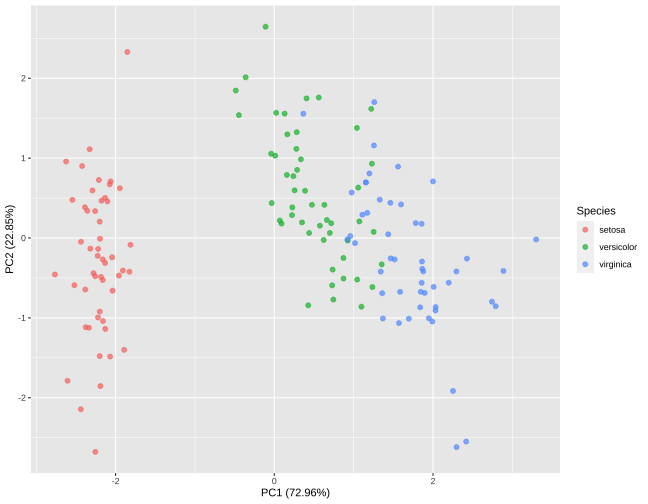<!-- --> ] --- class: center, middle # Pacote __caret__ - **C**lassification **A**nd **RE**gression **T**raining (Kuhn 2021) --- name: caret ## Interface para análise de dados do *caret* #### O pacote contem funções para simplificar tanto o treinamento de modelos para regressões e análises de classificação como a avaliação da efetividade dos modelos gerados. -- #### **Fluxo de processamento e análise de dados** -- Duas funções básicas: ``` caret::train() caret::trainControl() ``` --- ## Fluxograma de um perfil básico de análise .center2[ <img src="figuras/viz.png" width="70%" /> ] --- name: lda # Análise discriminante linear (LDA) Método de redução de dimensões ao mesmo tempo em que se retem o máximo de informação possível. O método ajuda a achar a combinação linear das variáveis originais que providenciam a melhor separação entre os grupos.<sup>1</sup> -- > Maximiza a medida inter-classes e minimiza a medida intra-classes. -- __Utilizada quando a variável *dependente* é *categórica*, e as variáveis *independentes* são *quantitativas*.__ -- Em R, utilizamos a função `lda()` do pacote `MASS` (Venables e Ripley 2002)<sup>2</sup>. -- Usando o `caret`, a função é a mesma, porém dentro de uma interface comum a vários métodos diferentes<sup>3</sup>. ``` r library("MASS") ``` .footnote2[ 1. Fávero, L. P., Belfiore, P., Silva, F. L. e Chan, B.L. (2009) Análise de dados: Modelagem multivariada para tomada de decisões. Rio de Janeiro: Elsevier. 2. Venables, W. N. e Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth Edition. 3. Lista completa de modelos aceitos no caret: <https://topepo.github.io/caret/available-models.html>. ] --- ## Premissas<sup>1</sup> * *Normalidade multivariada* * *Homogeneidade de variância/covariância* * *Independência entre as observações* -- *Multicolinearidade* pode diminuir o poder preditivo da classificação pois viola a independência das observações. .footnote[ 1. Fávero, L. P., Belfiore, P., Silva, F. L. e Chan, B.L. (2009) Análise de dados: Modelagem multivariada para tomada de decisões. Rio de Janeiro: Elsevier. ] --- ## Um exemplo - I - Execução Receita criada no slide [Criação da receita](#receita). .pull-left[ ``` r library("caret") ``` ] .pull-right[ ``` r ldafit_cvsimples <- train( treino_receita, treino, method = "lda", metric = "Accuracy" ) ``` ] --- ### Checagem de resultados ``` r ldafit_cvsimples ``` ``` ## Linear Discriminant Analysis ## ## 111 samples ## 4 predictor ## 3 classes: 'setosa', 'versicolor', 'virginica' ## ## Recipe steps: ## Resampling: Bootstrapped (25 reps) ## Summary of sample sizes: 111, 111, 111, 111, 111, 111, ... ## Resampling results: ## ## Accuracy Kappa ## 0.9754789 0.9627761 ``` --- ### Um exemplo - II - Medindo performance do `treino` ``` r getTrainPerf(ldafit_cvsimples) ``` ``` ## TrainAccuracy TrainKappa method ## 1 0.9754789 0.9627761 lda ``` --- ### Um exemplo - III - Predições e performance em `teste` .pull-left[ ``` r predicao_lda_basico <- ldafit_cvsimples %>% predict(., newdata = teste) predicao_lda_basico ``` ``` ## [1] setosa setosa setosa setosa setosa ## [6] setosa setosa setosa setosa setosa ## [11] setosa setosa setosa versicolor versicolor ## [16] versicolor versicolor versicolor versicolor versicolor ## [21] versicolor versicolor versicolor versicolor versicolor ## [26] versicolor virginica virginica virginica virginica ## [31] virginica virginica virginica virginica virginica ## [36] virginica virginica virginica virginica ## Levels: setosa versicolor virginica ``` ] --- ### Um exemplo - III - Predições e performance em `teste` .panelset.sideways[ .panel[.panel-name[Código] ``` r confusionMatrix(data = predicao_lda_basico, reference = teste$Species) ``` ] .panel[.panel-name[Resultado] <img src="./figuras/output_cfmatrix.png" style="width:750px;height:450px;"> ] ] .footnote2[ Para entender métricas de performance: <https://topepo.github.io/caret/measuring-performance.html#class>. ] --- ### Um exemplo - IV - Matriz de confusão .pull-left[ Função `confusao_lab()` do pacote `NIRtools`<sup>1</sup>. Caso não consigam ou não desejem instalar o pacote, basta fazer um `source()`: ``` r source("https://raw.githubusercontent.com/ricoperdiz/NIRtools/master/R/confusion_matrix.R") ``` ``` r par(mar = c(1, 5, 5, 1)) table(teste$Species, predicao_lda_basico) %>% confusao_lab(.) ``` ] .pull-right[ 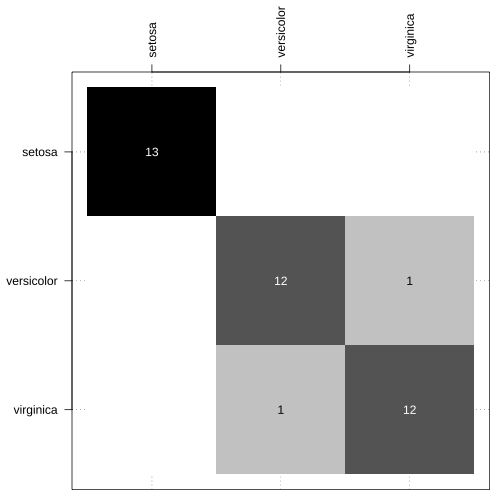<!-- --> ] .footnote2[ 1. Perdiz (2021) <https://github.com/ricoperdiz/NIRtools> ] --- ## Argumentos<sup>1</sup> para criação de modelos com a função `trainControl()` * `method`: _boot_, _cv_, _LOOCV_, _LGOCV_, _repeatedcv_ e _none_ (há mais opções!) * `number` e `repeats`: primeiro controla o número de divisões em _cv/repeatedcv_ OU número de iterações para _bootstrap_ e _LOOCV_; segundo se aplica somente ao k-fold. * `verboseIter`: Mostra um log * `returnData`: Retorna os dados que servem de entrada? * `p`: Porcentagem em _LGOCV_ * `classProbs`: valor lógico para determinar se as probabilidades de atribuição a cada classe devem ser calculadas * `returnResamp`: _all_, _final_ or _none_ * `allowParallel`: Paraleliza? .footnote2[ 1. Para uma lista completa, acesse a ajuda da função: `?trainControl` ] --- name: ctrl-cv ## Prática com `trainControl()` ### Validação cruzada *simples* - `cv` ``` r ctrl_cv <- trainControl(method = "cv", number = 10, # faz uma validacao 10-fold verboseIter = FALSE, returnData = TRUE, # Nao importante! Pode ser falso classProbs = TRUE, savePredictions = "all") ``` ``` r ldafit_cv_10fold <- train( treino_receita, treino, method = "lda", trControl = ctrl_cv, metric = "Accuracy" # em classificacoes, dois valores sao possiveis: Accuracy ou Kappa ) ``` --- #### Acessando o resultado de `train()` - I ``` r names(ldafit_cv_10fold) ``` ``` ## [1] "method" "modelInfo" "modelType" ## [4] "recipe" "results" "pred" ## [7] "bestTune" "call" "dots" ## [10] "metric" "control" "finalModel" ## [13] "trainingData" "resample" "resampledCM" ## [16] "perfNames" "maximize" "yLimits" ## [19] "times" "levels" "rs_seed" ``` Para acessar as informações, basta executar um dos comandos abaixo: .pull-left[ ``` r ldafit_cv_10fold$method # metodo utilizado ldafit_cv_10fold$modelInfo # info do modelo ldafit_cv_10fold$modelType # tipo de modelo ldafit_cv_10fold$bestTune ldafit_cv_10fold$call # formula utilizada em train() ldafit_cv_10fold$dots # se verbose == TRUE ou FALSE ldafit_cv_10fold$resample # estatisticas em cada reamostragem ldafit_cv_10fold$metric # qual metrica utilizada em train() ldafit_cv_10fold$control # especificacoes de trainControl() ``` ] --- #### Acessando o resultado de `train()` - II - Predições ``` r ldafit_cv_10fold$pred %>% filter(obs != pred) ``` ``` ## obs rowIndex pred setosa versicolor ## 1 versicolor 64 virginica 7.082366e-31 0.1304324 ## 2 virginica 99 versicolor 6.506261e-27 0.8282785 ## virginica parameter Resample ## 1 0.8695676 none Fold07 ## 2 0.1717215 none Fold10 ``` --- #### Acessando o resultado de `train()` - IV - resultados .center[ ``` r ldafit_cv_10fold$results ``` ``` ## parameter Accuracy Kappa AccuracySD KappaSD ## 1 none 0.9818182 0.9723259 0.03833064 0.05834346 ``` ] --- #### Acessando o resultado de `train()` - V - Modelo final Resultado da LDA, caso fizéssemos uso da função `lda()`, referente ao modelo final: ``` r ldafit_cv_10fold$finalModel ``` ``` ## Call: ## lda(x, y) ## ## Prior probabilities of groups: ## setosa versicolor virginica ## 0.3333333 0.3333333 0.3333333 ## ## Group means: ## Sepal.Length Sepal.Width Petal.Length Petal.Width ## setosa 5.029730 3.440541 1.481081 0.2459459 ## versicolor 5.972973 2.751351 4.254054 1.3162162 ## virginica 6.610811 2.989189 5.616216 2.0405405 ## ## Coefficients of linear discriminants: ## LD1 LD2 ## Sepal.Length 0.9107941 -0.6076288 ## Sepal.Width 1.3721594 2.7462192 ## Petal.Length -2.1944206 -0.2260993 ## Petal.Width -2.8023531 1.9159240 ## ## Proportion of trace: ## LD1 LD2 ## 0.9893 0.0107 ``` --- #### Medindo performance do `treino` ``` r getTrainPerf(ldafit_cv_10fold) ``` ``` ## TrainAccuracy TrainKappa method ## 1 0.9818182 0.9723259 lda ``` --- #### Predições e performance em `teste` .panelset.sideways[ .panel[.panel-name[Código] ``` r predicao_lda_cv_10fold <- ldafit_cv_10fold %>% predict(., newdata = teste) confusionMatrix(data = predicao_lda_cv_10fold, reference = teste$Species) ``` ] .panel[.panel-name[Resultado] <img src="./figuras/predicao_lda_cv_10fold.png" style="width:750px;height:450px;"> ] ] --- #### Matriz de confusão .pull-left[ Função `confusao_lab()` do pacote `NIRtools`<sup>1</sup>. ``` r par(mar = c(1, 5, 5, 1)) table(teste$Species, predicao_lda_basico) %>% NIRtools::confusao_lab(., add_CP = TRUE) ``` ] .pull-right[ 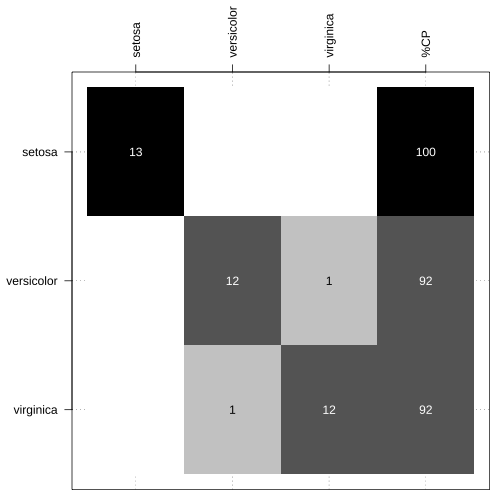<!-- --> ] .footnote2[ 1. Perdiz (2021) <https://github.com/ricoperdiz/NIRtools> ] --- ### Validação cruzada *repetida* - `repeatedcv` .pull-left[ ``` r ctrl_lda_repeatedcv <- trainControl( method = "repeatedcv", number = 10, # faz uma validacao 10-fold repeats = 10, verboseIter = FALSE, returnData = FALSE, # Nao importante! Pode ser falso classProbs = TRUE, savePredictions = "all" ) ``` ] .pull-right[ ``` r ldafit_repeatedcv_10fold_10vezes <- train( treino_receita, treino, method = "lda", trControl = ctrl_lda_repeatedcv, metric = "Accuracy" # em classificacoes, dois valores sao possiveis: Accuracy ou Kappa ) ``` ] --- ## Receitas de pré-processamento e o *caret* ### Por que aprender isso? -- #### Mais possibilidades no pré-processamento dos dados #### Manter variáveis adicionais para medir performance --- ## E o caret sem receita, pode? -- ### **Pode!** .pull-left[ #### Execução ``` r resultado_lda_sem_receita_basico <- train( Species ~ ., data = treino, method = "lda", metric = "Accuracy" ) ``` ] .pull-right[ #### Checagem de resultado ``` r print(resultado_lda_sem_receita_basico) ``` ``` ## Linear Discriminant Analysis ## ## 111 samples ## 4 predictor ## 3 classes: 'setosa', 'versicolor', 'virginica' ## ## No pre-processing ## Resampling: Bootstrapped (25 reps) ## Summary of sample sizes: 111, 111, 111, 111, 111, 111, ... ## Resampling results: ## ## Accuracy Kappa ## 0.9667379 0.9495212 ``` ] --- #### Medindo performance do `treino` ``` r getTrainPerf(resultado_lda_sem_receita_basico) ``` ``` ## TrainAccuracy TrainKappa method ## 1 0.9667379 0.9495212 lda ``` --- #### Predições e performance em `teste` .center[ ``` r predicao_lda_sem_receita_basico <- resultado_lda_sem_receita_basico %>% predict(., newdata = teste) confusionMatrix(data = predicao_lda_sem_receita_basico, reference = teste$Species) ``` ``` ## Confusion Matrix and Statistics ## ## Reference ## Prediction setosa versicolor virginica ## setosa 13 0 0 ## versicolor 0 13 0 ## virginica 0 0 13 ## ## Overall Statistics ## ## Accuracy : 1 ## 95% CI : (0.9097, 1) ## No Information Rate : 0.3333 ## P-Value [Acc > NIR] : < 2.2e-16 ## ## Kappa : 1 ## ## Mcnemar's Test P-Value : NA ## ## Statistics by Class: ## ## Class: setosa Class: versicolor ## Sensitivity 1.0000 1.0000 ## Specificity 1.0000 1.0000 ## Pos Pred Value 1.0000 1.0000 ## Neg Pred Value 1.0000 1.0000 ## Prevalence 0.3333 0.3333 ## Detection Rate 0.3333 0.3333 ## Detection Prevalence 0.3333 0.3333 ## Balanced Accuracy 1.0000 1.0000 ## Class: virginica ## Sensitivity 1.0000 ## Specificity 1.0000 ## Pos Pred Value 1.0000 ## Neg Pred Value 1.0000 ## Prevalence 0.3333 ## Detection Rate 0.3333 ## Detection Prevalence 0.3333 ## Balanced Accuracy 1.0000 ``` ] --- #### Matriz de confusão .pull-left[ Função `confusao_lab()` do pacote `NIRtools`<sup>1</sup>. ``` r par(mar = c(1, 5, 5, 1)) table(teste$Species, predicao_lda_sem_receita_basico) %>% NIRtools::confusao_lab(.) ``` ] .pull-right[ <!-- --> ] .footnote2[ 1. Perdiz (2021) <https://github.com/ricoperdiz/NIRtools> ] --- name: pls # Análise de mínimos quadrados parciais (PLS) Método muito utilizado na quimiometria, especialmente quando o número de variáveis preditoras é significantemente maior que o número de observações. -- Baseia-se em variáveis latentes, em que cada fator é definido como uma combinação linear das variáveis originais das variáveis preditoras ou variável resposta. -- > Essencialmente, trata-se de uma versão *supervisionada* da PCA<sup>1</sup> ``` r library("pls") ``` .footnote2[ 1. Kuhn (2021) <https://topepo.github.io/caret/using-your-own-model-in-train.html#illustrative-example-4-pls-feature-extraction-pre-processing>. ] --- name: pls-cv ## **PLS** com o pacote `caret` -- ### Dados Mesmo conjunto de dados utilizado anteriormente. Coloco aqui para facilitar a preparação dos dados para a PLS. ``` r dados <- iris dados <- as_tibble(dados) dados_split <- initial_split(dados, strata = "Species") treino <- training(dados_split) teste <- testing(dados_split) treino_receita <- recipes::recipe(Species ~ ., data = treino) %>% prep() ``` --- ### Execução .pull-left[ ``` r ctrl_exemplo_pls <- trainControl( method = "repeatedcv", number = 10, repeats = 10, verboseIter = FALSE, savePredictions = "final") ``` ] .pull-right[ ``` r plsfit_exemplo <- train( treino_receita, treino, method = "pls", metric = "Accuracy", trControl = ctrl_exemplo_pls, tuneLength = 3 ) ``` ] ??? É importante comentar sobre a utilidade do argumento `tuneGrid` da função `train()` quando executamos uma PLS. Também comentar sobre a possibilidade de paralelização da análise por meio do pacote `paralell` e a função `registerDoParallel`. --- ### Checando o resultado ``` r plsfit_exemplo ``` ``` ## Partial Least Squares ## ## 111 samples ## 4 predictor ## 3 classes: 'setosa', 'versicolor', 'virginica' ## ## Recipe steps: ## Resampling: Cross-Validated (10 fold, repeated 10 times) ## Summary of sample sizes: 99, 99, 99, 101, 100, 99, ... ## Resampling results across tuning parameters: ## ## ncomp Accuracy Kappa ## 1 0.6704242 0.5055691 ## 2 0.7864798 0.6787244 ## 3 0.7934949 0.6889434 ## ## Accuracy was used to select the optimal model using ## the largest value. ## The final value used for the model was ncomp = 3. ``` --- ### Acurácia por número de componentes ``` r plot(plsfit_exemplo) ``` <!-- --> --- ### Predições e performance ``` r plsfit_exemplo %>% predict(newdata = teste) %>% confusionMatrix(data = ., reference = teste$Species) ``` ``` ## Confusion Matrix and Statistics ## ## Reference ## Prediction setosa versicolor virginica ## setosa 13 0 0 ## versicolor 0 8 3 ## virginica 0 5 10 ## ## Overall Statistics ## ## Accuracy : 0.7949 ## 95% CI : (0.6354, 0.907) ## No Information Rate : 0.3333 ## P-Value [Acc > NIR] : 4.429e-09 ## ## Kappa : 0.6923 ## ## Mcnemar's Test P-Value : NA ## ## Statistics by Class: ## ## Class: setosa Class: versicolor ## Sensitivity 1.0000 0.6154 ## Specificity 1.0000 0.8846 ## Pos Pred Value 1.0000 0.7273 ## Neg Pred Value 1.0000 0.8214 ## Prevalence 0.3333 0.3333 ## Detection Rate 0.3333 0.2051 ## Detection Prevalence 0.3333 0.2821 ## Balanced Accuracy 1.0000 0.7500 ## Class: virginica ## Sensitivity 0.7692 ## Specificity 0.8077 ## Pos Pred Value 0.6667 ## Neg Pred Value 0.8750 ## Prevalence 0.3333 ## Detection Rate 0.2564 ## Detection Prevalence 0.3846 ## Balanced Accuracy 0.7885 ``` --- ## Validação cruzada *Leave-one-out* - `LOOCV` .pull-left[ ``` r ctrl_loocv <- trainControl( method = "LOOCV", verboseIter = FALSE, savePredictions = "final") ``` ] .pull-right[ ``` r plsfit_exemplo_loocv <- train( treino_receita, treino, method = "pls", metric = "Accuracy", trControl = ctrl_loocv, tuneGrid = expand.grid(ncomp = 2) ) ``` ] --- ### Checagem de resultado ``` r plsfit_exemplo_loocv ``` ``` ## Partial Least Squares ## ## 111 samples ## 4 predictor ## 3 classes: 'setosa', 'versicolor', 'virginica' ## ## Recipe steps: ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 110, 110, 110, 110, 110, 110, ... ## Resampling results: ## ## Accuracy Kappa ## 0.7747748 0.6621622 ## ## Tuning parameter 'ncomp' was held constant at a value of 2 ``` --- ### Medindo performance do `treino` ``` r getTrainPerf(plsfit_exemplo_loocv) ``` ``` ## TrainAccuracy TrainKappa method ## 1 0.7747748 0.6621622 pls ``` --- ### Predições e performance em `teste` .panelset.sideways[ .panel[.panel-name[Código] ``` r predicao_plsfit_exemplo_loocv <- plsfit_exemplo_loocv %>% predict(., newdata = teste) confusionMatrix(data = predicao_plsfit_exemplo_loocv, reference = teste$Species) ``` ``` ## Confusion Matrix and Statistics ## ## Reference ## Prediction setosa versicolor virginica ## setosa 13 0 0 ## versicolor 0 9 2 ## virginica 0 4 11 ## ## Overall Statistics ## ## Accuracy : 0.8462 ## 95% CI : (0.6947, 0.9414) ## No Information Rate : 0.3333 ## P-Value [Acc > NIR] : 5.641e-11 ## ## Kappa : 0.7692 ## ## Mcnemar's Test P-Value : NA ## ## Statistics by Class: ## ## Class: setosa Class: versicolor ## Sensitivity 1.0000 0.6923 ## Specificity 1.0000 0.9231 ## Pos Pred Value 1.0000 0.8182 ## Neg Pred Value 1.0000 0.8571 ## Prevalence 0.3333 0.3333 ## Detection Rate 0.3333 0.2308 ## Detection Prevalence 0.3333 0.2821 ## Balanced Accuracy 1.0000 0.8077 ## Class: virginica ## Sensitivity 0.8462 ## Specificity 0.8462 ## Pos Pred Value 0.7333 ## Neg Pred Value 0.9167 ## Prevalence 0.3333 ## Detection Rate 0.2821 ## Detection Prevalence 0.3846 ## Balanced Accuracy 0.8462 ``` ] .panel[.panel-name[Resultado] <img src="./figuras/plsfit_exemplo_loocv.png" style="width:750px;height:450px;"> ] ] --- ### Matriz de confusão .pull-left[ Função `confusao_lab()` do pacote `NIRtools`<sup>1</sup>. ``` r par(mar = c(1, 5, 5, 1)) table(teste$Species, predicao_plsfit_exemplo_loocv) %>% NIRtools::confusao_lab(.) ``` ] .pull-right[ <!-- --> ] .footnote2[ 1. Perdiz (2021) <https://github.com/ricoperdiz/NIRtools> ] --- # Resumo de construção e avaliação de modelos com a interface *caret* * `trainControl()` e `train()` - controla argumentos e treina modelos * `getTrainPerf()` avalia o modelo com dados `treino` * `predict()` para predizer categoria das amostras em `teste` * `confusionMatrix()` para obter métricas de performance e matriz de confusão * `confusao_lab` para plotar uma matriz de confusão no estilo LABOTAM. --- class: top background-image: url("figuras/agradecimento.jpeg") background-size: cover ### Grato! .pull-right[  [<svg viewBox="0 0 496 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <path d="M165.9 397.4c0 2-2.3 3.6-5.2 3.6-3.3.3-5.6-1.3-5.6-3.6 0-2 2.3-3.6 5.2-3.6 3-.3 5.6 1.3 5.6 3.6zm-31.1-4.5c-.7 2 1.3 4.3 4.3 4.9 2.6 1 5.6 0 6.2-2s-1.3-4.3-4.3-5.2c-2.6-.7-5.5.3-6.2 2.3zm44.2-1.7c-2.9.7-4.9 2.6-4.6 4.9.3 2 2.9 3.3 5.9 2.6 2.9-.7 4.9-2.6 4.6-4.6-.3-1.9-3-3.2-5.9-2.9zM244.8 8C106.1 8 0 113.3 0 252c0 110.9 69.8 205.8 169.5 239.2 12.8 2.3 17.3-5.6 17.3-12.1 0-6.2-.3-40.4-.3-61.4 0 0-70 15-84.7-29.8 0 0-11.4-29.1-27.8-36.6 0 0-22.9-15.7 1.6-15.4 0 0 24.9 2 38.6 25.8 21.9 38.6 58.6 27.5 72.9 20.9 2.3-16 8.8-27.1 16-33.7-55.9-6.2-112.3-14.3-112.3-110.5 0-27.5 7.6-41.3 23.6-58.9-2.6-6.5-11.1-33.3 2.6-67.9 20.9-6.5 69 27 69 27 20-5.6 41.5-8.5 62.8-8.5s42.8 2.9 62.8 8.5c0 0 48.1-33.6 69-27 13.7 34.7 5.2 61.4 2.6 67.9 16 17.7 25.8 31.5 25.8 58.9 0 96.5-58.9 104.2-114.8 110.5 9.2 7.9 17 22.9 17 46.4 0 33.7-.3 75.4-.3 83.6 0 6.5 4.6 14.4 17.3 12.1C428.2 457.8 496 362.9 496 252 496 113.3 383.5 8 244.8 8zM97.2 352.9c-1.3 1-1 3.3.7 5.2 1.6 1.6 3.9 2.3 5.2 1 1.3-1 1-3.3-.7-5.2-1.6-1.6-3.9-2.3-5.2-1zm-10.8-8.1c-.7 1.3.3 2.9 2.3 3.9 1.6 1 3.6.7 4.3-.7.7-1.3-.3-2.9-2.3-3.9-2-.6-3.6-.3-4.3.7zm32.4 35.6c-1.6 1.3-1 4.3 1.3 6.2 2.3 2.3 5.2 2.6 6.5 1 1.3-1.3.7-4.3-1.3-6.2-2.2-2.3-5.2-2.6-6.5-1zm-11.4-14.7c-1.6 1-1.6 3.6 0 5.9 1.6 2.3 4.3 3.3 5.6 2.3 1.6-1.3 1.6-3.9 0-6.2-1.4-2.3-4-3.3-5.6-2z"></path></svg> @ricoperdiz](https://github.com/ricoperdiz) [<svg viewBox="0 0 512 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <path d="M459.37 151.716c.325 4.548.325 9.097.325 13.645 0 138.72-105.583 298.558-298.558 298.558-59.452 0-114.68-17.219-161.137-47.106 8.447.974 16.568 1.299 25.34 1.299 49.055 0 94.213-16.568 130.274-44.832-46.132-.975-84.792-31.188-98.112-72.772 6.498.974 12.995 1.624 19.818 1.624 9.421 0 18.843-1.3 27.614-3.573-48.081-9.747-84.143-51.98-84.143-102.985v-1.299c13.969 7.797 30.214 12.67 47.431 13.319-28.264-18.843-46.781-51.005-46.781-87.391 0-19.492 5.197-37.36 14.294-52.954 51.655 63.675 129.3 105.258 216.365 109.807-1.624-7.797-2.599-15.918-2.599-24.04 0-57.828 46.782-104.934 104.934-104.934 30.213 0 57.502 12.67 76.67 33.137 23.715-4.548 46.456-13.32 66.599-25.34-7.798 24.366-24.366 44.833-46.132 57.827 21.117-2.273 41.584-8.122 60.426-16.243-14.292 20.791-32.161 39.308-52.628 54.253z"></path></svg> @ricoperdiz](https://twitter.com/ricoperdiz) [<svg viewBox="0 0 512 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <path d="M326.612 185.391c59.747 59.809 58.927 155.698.36 214.59-.11.12-.24.25-.36.37l-67.2 67.2c-59.27 59.27-155.699 59.262-214.96 0-59.27-59.26-59.27-155.7 0-214.96l37.106-37.106c9.84-9.84 26.786-3.3 27.294 10.606.648 17.722 3.826 35.527 9.69 52.721 1.986 5.822.567 12.262-3.783 16.612l-13.087 13.087c-28.026 28.026-28.905 73.66-1.155 101.96 28.024 28.579 74.086 28.749 102.325.51l67.2-67.19c28.191-28.191 28.073-73.757 0-101.83-3.701-3.694-7.429-6.564-10.341-8.569a16.037 16.037 0 0 1-6.947-12.606c-.396-10.567 3.348-21.456 11.698-29.806l21.054-21.055c5.521-5.521 14.182-6.199 20.584-1.731a152.482 152.482 0 0 1 20.522 17.197zM467.547 44.449c-59.261-59.262-155.69-59.27-214.96 0l-67.2 67.2c-.12.12-.25.25-.36.37-58.566 58.892-59.387 154.781.36 214.59a152.454 152.454 0 0 0 20.521 17.196c6.402 4.468 15.064 3.789 20.584-1.731l21.054-21.055c8.35-8.35 12.094-19.239 11.698-29.806a16.037 16.037 0 0 0-6.947-12.606c-2.912-2.005-6.64-4.875-10.341-8.569-28.073-28.073-28.191-73.639 0-101.83l67.2-67.19c28.239-28.239 74.3-28.069 102.325.51 27.75 28.3 26.872 73.934-1.155 101.96l-13.087 13.087c-4.35 4.35-5.769 10.79-3.783 16.612 5.864 17.194 9.042 34.999 9.69 52.721.509 13.906 17.454 20.446 27.294 10.606l37.106-37.106c59.271-59.259 59.271-155.699.001-214.959z"></path></svg> ricardoperdiz.com](https://ricardoperdiz.com) [<svg viewBox="0 0 512 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <path d="M440 6.5L24 246.4c-34.4 19.9-31.1 70.8 5.7 85.9L144 379.6V464c0 46.4 59.2 65.5 86.6 28.6l43.8-59.1 111.9 46.2c5.9 2.4 12.1 3.6 18.3 3.6 8.2 0 16.3-2.1 23.6-6.2 12.8-7.2 21.6-20 23.9-34.5l59.4-387.2c6.1-40.1-36.9-68.8-71.5-48.9zM192 464v-64.6l36.6 15.1L192 464zm212.6-28.7l-153.8-63.5L391 169.5c10.7-15.5-9.5-33.5-23.7-21.2L155.8 332.6 48 288 464 48l-59.4 387.3z"></path></svg> ricoperdiz@gmail.com](mailto:ricoperdiz@gmail.com) ] --- # Info do sistema ``` ## R version 4.5.1 (2025-06-13 ucrt) ## Platform: x86_64-w64-mingw32/x64 ## Running under: Windows 11 x64 (build 26100) ## ## Matrix products: default ## LAPACK version 3.12.1 ## ## locale: ## [1] LC_COLLATE=Portuguese_Brazil.utf8 ## [2] LC_CTYPE=Portuguese_Brazil.utf8 ## [3] LC_MONETARY=Portuguese_Brazil.utf8 ## [4] LC_NUMERIC=C ## [5] LC_TIME=Portuguese_Brazil.utf8 ## ## time zone: America/Manaus ## tzcode source: internal ## ## attached base packages: ## [1] stats graphics grDevices utils datasets ## [6] methods base ## ## other attached packages: ## [1] pls_2.8-5 MASS_7.3-65 ## [3] metathis_1.1.4.9000 data.table_1.17.0 ## [5] magrittr_2.0.3 caret_7.0-1 ## [7] lattice_0.22-7 yardstick_1.3.2 ## [9] workflowsets_1.1.0 workflows_1.2.0 ## [11] tune_1.3.0 tidyr_1.3.1 ## [13] tibble_3.2.1 rsample_1.3.0 ## [15] recipes_1.2.1 purrr_1.0.4 ## [17] parsnip_1.3.1 modeldata_1.4.0 ## [19] infer_1.0.8 dplyr_1.1.4 ## [21] dials_1.4.0 scales_1.3.0 ## [23] broom_1.0.8 tidymodels_1.3.0 ## [25] ggplot2_3.5.2 xaringanthemer_0.4.3.9000 ## [27] rsvg_2.6.2 DiagrammeRsvg_0.1 ## [29] DiagrammeR_1.0.11.9000 ## ## loaded via a namespace (and not attached): ## [1] pROC_1.18.5 rlang_1.1.6 ## [3] furrr_0.3.1 e1071_1.7-16 ## [5] compiler_4.5.1 png_0.1-8 ## [7] vctrs_0.6.5 reshape2_1.4.4 ## [9] lhs_1.2.0 stringr_1.5.1 ## [11] sysfonts_0.8.9 pkgconfig_2.0.3 ## [13] fastmap_1.2.0 backports_1.5.0 ## [15] labeling_0.4.3 utf8_1.2.4 ## [17] promises_1.3.2 rmarkdown_2.29 ## [19] prodlim_2024.06.25 xfun_0.52.1 ## [21] showtext_0.9-7 cachem_1.1.0 ## [23] jsonlite_2.0.0 later_1.4.2 ## [25] parallel_4.5.1 R6_2.6.1 ## [27] bslib_0.9.0 stringi_1.8.7 ## [29] RColorBrewer_1.1-3 parallelly_1.43.0 ## [31] rpart_4.1.24 lubridate_1.9.4 ## [33] jquerylib_0.1.4 Rcpp_1.0.14 ## [35] iterators_1.0.14 knitr_1.50 ## [37] future.apply_1.11.3 NIRtools_0.0.0.9006 ## [39] httpuv_1.6.15 Matrix_1.7-3 ## [41] splines_4.5.1 nnet_7.3-20 ## [43] timechange_0.3.0 tidyselect_1.2.1 ## [45] rstudioapi_0.17.1 yaml_2.3.10 ## [47] timeDate_4041.110 codetools_0.2-20 ## [49] curl_6.2.2 listenv_0.9.1 ## [51] plyr_1.8.9 withr_3.0.2 ## [53] evaluate_1.0.3 xaringan_0.30.1 ## [55] future_1.40.0 survival_3.8-3 ## [57] proxy_0.4-27 xml2_1.3.8 ## [59] pillar_1.10.2 rsconnect_1.3.4 ## [61] whisker_0.4.1 stats4_4.5.1 ## [63] foreach_1.5.2 generics_0.1.3 ## [65] icons_0.2.0 servr_0.32 ## [67] munsell_0.5.1 globals_0.16.3 ## [69] class_7.3-23 glue_1.8.0 ## [71] tools_4.5.1 xaringanExtra_0.8.0.9000 ## [73] ModelMetrics_1.2.2.2 gower_1.0.2 ## [75] visNetwork_2.1.2 grid_4.5.1 ## [77] ipred_0.9-15 colorspace_2.1-1 ## [79] nlme_3.1-168 showtextdb_3.0 ## [81] cli_3.6.4 DiceDesign_1.10 ## [83] rappdirs_0.3.3 lava_1.8.1 ## [85] V8_6.0.3 gtable_0.3.6 ## [87] GPfit_1.0-9 sass_0.4.10 ## [89] digest_0.6.37 farver_2.1.2 ## [91] htmlwidgets_1.6.4 htmltools_0.5.8.1 ## [93] lifecycle_1.0.4 hardhat_1.4.1 ## [95] mime_0.13 ```